
Python读写Excel文件
Microsoft Excel 几乎无处不在,使用 Excel 既可以保存客户、库存和雇员数据,还可以跟踪运营、销售和财务活动。人们在商业活动中使用 Excel 的方式五花八门,难以计数。
与 Python 的 csv 模块不同,Python 中没有处理 Excel 文件(就是带有 .xls 和 .xlsx 扩展名的文件)的标准模块。xlrd 和 xlwt 扩展包使 Python 可以在任何操作系统上处理 Excel 文件,而且对 Excel 日期型数据的支持非常好.
内省Excel工作簿
Excel 文件与 CSV 文件至少在两个重要方面有所不同。
- 与CSV 文件不同,Excel 文件不是纯文本文件,所以你不能在文本编辑器中打开它并查看数据
- 与 CSV 文件不同,一个 Excel 工作簿被设计成包含多个工作表,
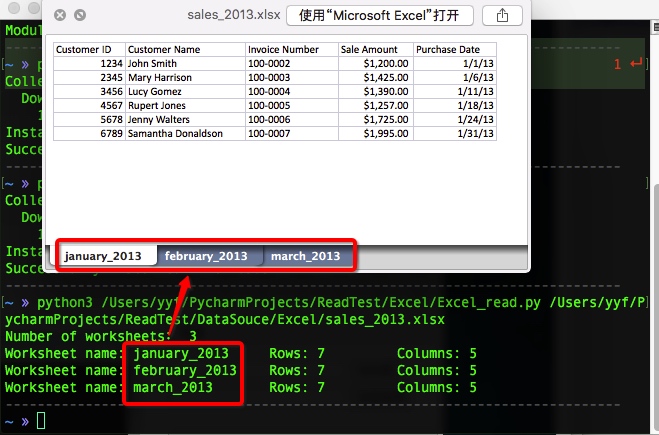
所以需要知道在不用手动打开工作簿的前提下,如何通过工作簿内省(也就是内部检查)获取其中所有工作表的信息。通过内省一个工作簿,你可以在实际开始处理工作簿中的数据之前,检查工作表的数目和每个工作表中的数据类型和数据量。
内省 Excel 文件有助于确定文件中的数据确实是你需要的,并对数据一致性和完整性做一个初步检查。弄清楚输入文件的数量,以及每个文件中的行数和列数,可以使你对数据处理工作的工作量和文件内容的一致性有个大致的概念。
本节中的演示代码只解释新添加的。没有添加的都是在CSV文件读写的里面。
确定工作簿中工作表的数量、名称和每个工作表中行列的数量
1 | import sys |
处理单个工作表
1. 读写Excel文件
基础Python + xlrd + xlwt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import sys
from xlrd import open_workbook
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
#生产workbook对象,以使我们可以将结果写入用于输出的Excel文件
output_workbook = Workbook()
#为输出工作簿添加一个工作表
output_worksheet = output_workbook.add_sheet('jan_2013_output')
with open_workbook(input_file) as workbook:
#引用名字是‘january_2013’的工作表
worksheet = workbook.sheet_by_name('january_2013')
#迭代行、列
for row_index in range(worksheet.nrows):
for column_index in range(worksheet.ncols):
#使用 xlwt 的 write 函数和行与列的索引将每个单元格的值写入输出文件的工作表
output_worksheet.write(row_index,
column_index,
worksheet.cell_value(row_index,column_index))
#保存关闭
output_workbook.save(output_file)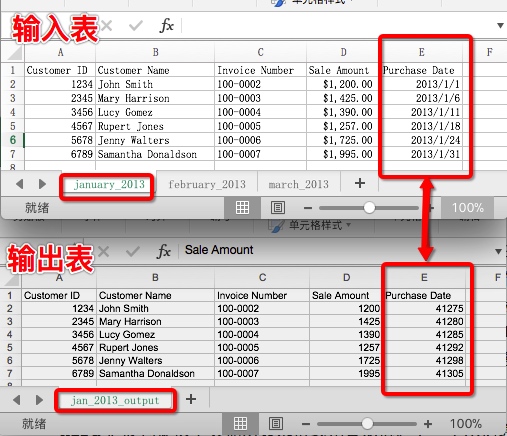
E 列的日期变成了数字。数值 1 代表 1900 年 1 月 1 日,因为从 1900 年 1 月 0 日过去了 1 天,所以输出表的
Purchase Date没有格式化。xlrd 扩展包提供了其他函数来格式化日期值。xlrd API文档。转换时间格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45import sys
#可以将数值转换成日期并对日期进行格式化。
from datetime import date
#open_workbook 打开Excel工作簿
#xldate_as_tuple 将Excel中的日期、时间或日期时间的数值转换成玉足,
# 这样就可以提取出具体的元素,并转成不同的格式
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
for row_index in range(worksheet.nrows):
row_list_output = []
for col_index in range(worksheet.ncols):
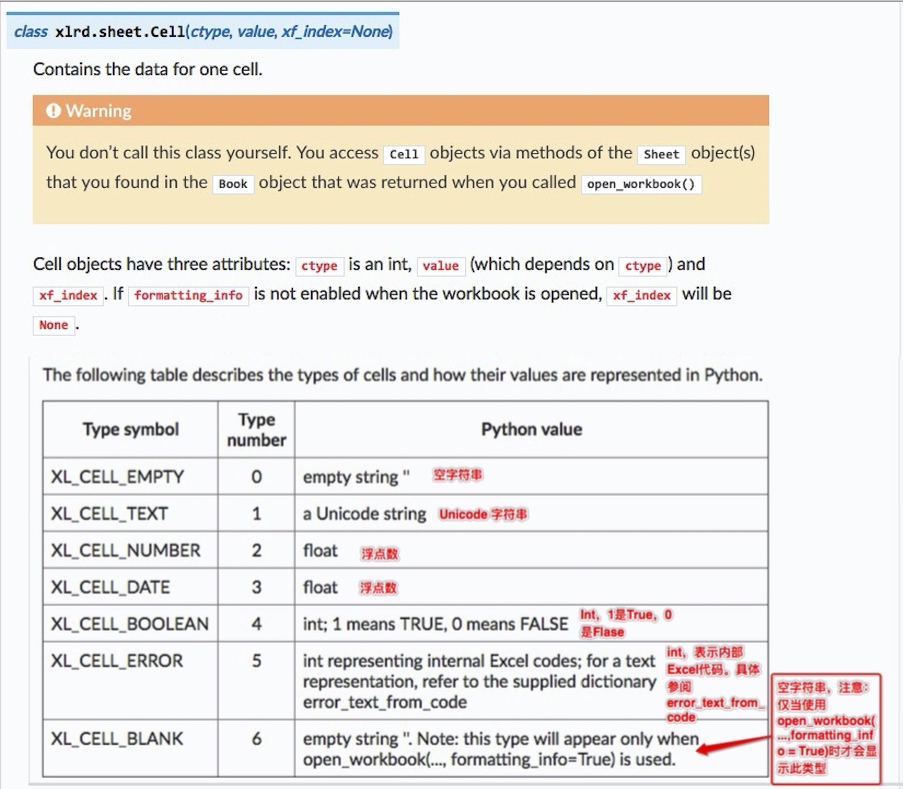
# 判断单元格里的值是否是日期数据
if worksheet.cell_type(row_index,col_index)==3:
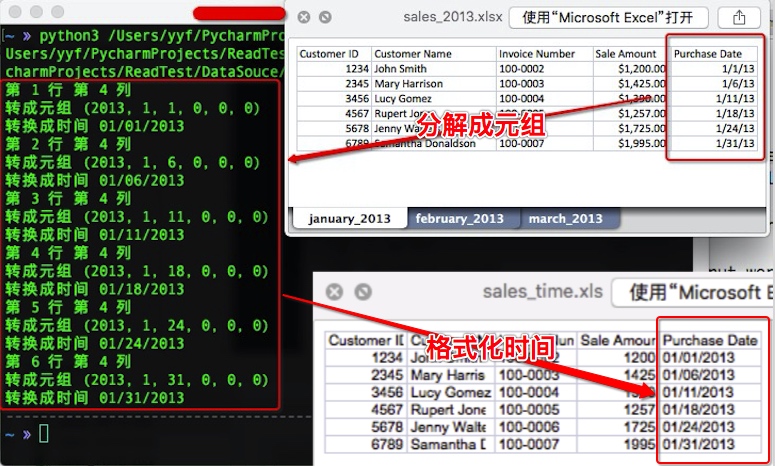
print('第 %d 行' % row_index,'第 %d 列' % col_index)
# 先将单元格里的表示日期数值转换成元组
# 使用cell_value 函数和行列索引来引用单元格中的值,或者使用 cell().value
# workbook.datemode 为了确定是从1900年还是1904年开始计算的
date_cell = xldate_as_tuple(worksheet.cell_value(row_index,col_index),
workbook.datemode)
print('转成元组',date_cell)
# 使用元组的索引来引用元组的前三个元素并将它们作为参数传递给date函数来转换成date对象,
# 用strftime()函数来将date对象转换成特定格式的字符串
# 前3个元素也就是年、月、日
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
print('转换成时间', date_cell)
row_list_output.append(date_cell)
# 写入对应的格式化的日期
output_worksheet.write(row_index,col_index,date_cell)
else:
# 将sheet中非表示日期的值赋给non_date_celld对象
non_date_cell = worksheet.cell_value(row_index,col_index)
row_list_output.append(non_date_cell)
# 将sheet中非日期的值位置填充到相应位置
output_worksheet.write(row_index,col_index,non_date_cell)
output_workbook.save(output_file)
参数 workbook.datemode 是必需的,它可以使函数确定日期是基于 1900 年还是基于 1904 年,并据此将数值转换成正确的元组(在 Mac 上的某些 Excel 版本从 1904 年 1 月 1 日开始计算日期。可以参看微软的文档《Excel中1900和1904年日期系统之间的区别》。
1
2
3
4
5
6
7
8
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame =pd.read_excel(input_file,sheetname='january_2013')
writer = pd.ExcelWriter(output_file)
data_frame.to_excel(writer,sheet_name = 'jan_13_output',index=False)
writer.save()
2. 筛选特定行
1. 行中的值满足某个条件
任务:筛选出Sale Amount 大于¥1400的行
- 基础Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
#定位SaleAmount列
sale_amount_column_index = 3
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
#输入文件中要写入输出文件的行的列表
data = []
#提取标题
header = worksheet.row_values(0)
data.append(header)
for row_index in range(1,worksheet.nrows):
row_list = []
#保存销售额
sale_amount = worksheet.cell_value(row_index,sale_amount_column_index)
#判断销售额是否大于1400的行
if sale_amount > 1400.0:
for column_index in range(worksheet.ncols):
#提取每个单元格的值
cell_value = worksheet.cell_value(row_index,column_index)
#提取每个单元格的类型
cell_type = worksheet.cell_type(row_index,column_index)
#判断是否是日期类型
if cell_type == 3:
#格式化日期
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
#判断是否为空
if row_list:
data.append(row_list)
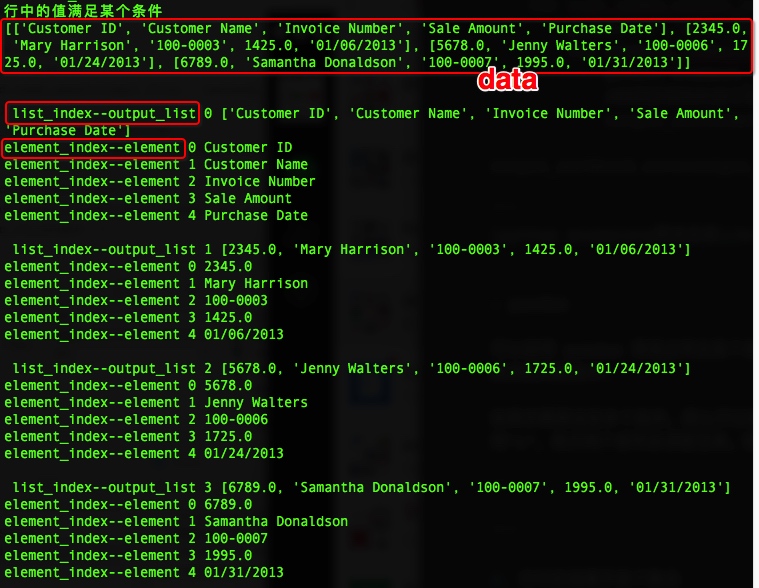
print(data,'\n')
#迭代data并写入输出文件
# enumerate 可以得到新的连续索引,要不就会继续使用输入文件的索引
for list_index,output_list in enumerate(data):
print('\n','list_index--output_list',list_index,output_list)
for element_index,element in enumerate(output_list):
print('element_index--element',element_index, element)
#按照新得到的索引填入数据
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
- pandas
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
data_frame_value_meets_condition = \
data_frame[data_frame['Sale Amount'].astype(float)>1400]
writer = pd.ExcelWriter(output_file)
data_frame_value_meets_condition.to_excel(writer,
sheet_name = 'jan_13_output',
index=False)
writer.save()
可以使用 pandas 筛选出符合某个条件的行,指定你想判断的列的名称,并在数据框名称后面的方括号中设定具体的判断条件.
如果你需要设定多个条件,那么可以将这些条件放在圆括号中,根据需要的逻辑顺序用“&”或“|”连接起来。使用“&”,表示两个条件必须都为真。使用“|”,表示只要一个条件为真就可以。
1
2
3
4
5
data_frame[(data_frame['Sale Amount'].astype(float)>1400)
& (data_frame['Customer ID'].astype(float) < 3000)]
data_frame[(data_frame['Sale Amount'].astype(float)>1400)
| (data_frame['Customer ID'].astype(float) < 3000)]
2. 行中的值属于某个集合
> 任务:购买日期是'01/24/2013','01/31/2013'这两个日期的
- 基础Python + xlwt + xlrd 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import sys
from datetime import date
from xlwt import Workbook
from xlrd import open_workbook,xldate_as_tuple
input_file = sys.argv[1]
output_fiel = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
important_dates = ['01/24/2013','01/31/2013']
purchase_date_column_index=4
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
header = worksheet.row_values(0)
data.append(header)
for row_index in range(1,worksheet.nrows):
purchase_date_time = \
xldate_as_tuple(worksheet.cell_value(row_index,purchase_date_column_index)
,workbook.datemode)
purchase_date = date(*purchase_date_time[0:3]).strftime('%m/%d/%Y')
row_list = []
#判断是否在important_dates中
if purchase_date in important_dates:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type ==3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_fiel)
- pandas 实现
1
2
3
4
5
6
7
8
9
10
11
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
important_datas = ['01/24/2013','01/31/2013']
data_frame_value_in_set = data_frame[data_frame['Purchase Date'].isin(important_datas)]
writer = pd.ExcelWriter(output_file)
data_frame_value_in_set.to_excel(writer,sheet_name = 'jan_13_output',index=False)
writer.save()
3. 行中的值匹配与特定的正则表达式
> 任务:客户姓名以大写字母 J 开头
- python + re + xlrd + xlwt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import re,sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
# 使用re模块的compile函数创建一个正则表达式pattern
# ?P<my_pattern> 捕获了名为 <my_pattern> 的组中匹配了的子字符串
# ^J.* 符号(^ )表示“在字符串开头搜索模式” , (.*) 除换行符之外的任意字符
pattren = re.compile(r'(?P<my_pattern>^J.*)')
custom_name_column_index = 1
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
header = worksheet.row_values(0)
data.append(header)
for row_index in range(1,worksheet.nrows):
row_list = []
# 匹配
if pattren.search(worksheet.cell_value(row_index,custom_name_column_index)):
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type==3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index ,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
> ` pattren = re.compile(r'(?P<my_pattern>^J.*)') `
> r 表示单引号之间的模式是一个原始字符串。元字符 ?P<my_pattern> 捕获了名为 <my_pattern> 的组中匹配了的子字符串,以便在需要时将它们打印到屏幕上或写入文件。我们要搜索的实际模式是 ' ^J.* ' 。插入符号(^ )是一个特殊符号,表示“在字符串开头搜索模式”。所以,字符串需要以大写字母 J 开头。句点 . 可以匹配任何字符,除了换行符。所以除换行符之外的任何字符都可以跟在 J 后面。最后,* 表示重复前面的字符 0 次或更多次。.* 组合在一起用来表示除换行符之外的任意字符可以在 J 后面出现任意次。
- pandas
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
data_frame_value_matches_pattern = \
data_frame[data_frame['Customer Name'].str.startswith('J')]
writer = pd.ExcelWriter(output_file)
data_frame_value_matches_pattern.to_excel(writer,
sheet_name='jan_2013_output',
index = False)
writer.save()
3. 筛选特定列
1. 使用列索引值
从工作表中选取特定列的一种方法是使用要保留的列的**索引值**。当你想保留的列的索引值非常**容易识别**,或者在处理多个输入文件过程中,各个输入文件中**列的位置是一致(也就是不会发生改变)**的时候,这种方法非常有效。
> 任务:保留 Customer Name 和 Purchase Date 两列
- 基础Python + xlrd + xlwt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file =sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('jan_2013_output')
# 代表 CustomerName和Purchase Date
my_columns = [1,4]
with open_workbook(input_file) as workbook:
worksheet = workbook.sheet_by_name('january_2013')
data = []
for row_index in range(worksheet.nrows):
row_list = []
for column_index in my_columns:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
pandas
- 设置数据框,在方括号中列出要保留的列的索引值或者名称(字符串)
- 设置数据框和iloc函数。iloc函数可以同时选择特定的行与特定的列。所以使用iloc函数,就需要在列索引值前面加上一个冒号和一个逗号,表示想要为这些特定列保留所有行。否则,iloc函数也会使用这些索引值去筛选行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
data_frame_column_by_index = data_frame.iloc[:,[1,4]]
writer = pd.ExcelWriter(output_file)
data_frame_column_by_index.to_excel(writer,sheet_name = 'jan_2013_output',index=False)
writer.save()
#### 2. 使用列标题/列索引值
想保留的列的标题非常容易识别,或者在处理多个输入文件过程中,各个输入文件中列的位置会发生改变,但标题不变的时候,这种方法非常有效.
> 任务:保留 Customer Name 和 Purchase Date 两列。因为类似所以只展示根据列标题代码,跟据列索引的注释掉了。因为大同小异。
- 基础Python + xlrd + xlwt
```Python
import sys
from xlwt import Workbook
from xlrd import open_workbook,xldate_as_tuple
from datetime import date
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
#给输出文件中添加一个工作表
output_worksheet = output_workbook.add_sheet('jan_2013_output')
#要写入的数据添加标题
my_columns = ['Customer ID','Purchase Date']
#根据列索引
# my_columns_index = [0,4]
# my_columns = []
with open_workbook(input_file) as workbook:
#按工作表名打开
worksheet = workbook.sheet_by_name('january_2013')
#要写入的数据集合
data = []
#获取输入文件的标题
header_list = worksheet.row_values(0)
#创建存标题索引的列表
header_index_list = []
#根据列索引
# for title_index in range(len(header_list)):
# if title_index in my_columns_index:
# my_columns.append(header_list[title_index])
# 要写入的数据添加标题
data = [my_columns]
#迭代标题索引
for header_index in range(len(header_list)):
#判断标题是否是要写入的标题
if header_list[header_index] in my_columns:
#添加写入标题的索引
header_index_list.append(header_index)
#从索引是1的行也就是内容行开始遍历
for row_index in range(1,worksheet.nrows):
#创建要写入的内容列表
row_list = []
#遍历要写入的标题索引
for column_index in header_index_list:
#取出表格内容
cell_value = worksheet.cell_value(row_index,column_index)
#获取内容类型
cell_type = worksheet.cell_type(row_index,column_index)
#判断是否是日期类型
if cell_type ==3:
#把日期数据转换更元组
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
#取出日期元组中的前3个,格式化
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
#添加到要写入的行list中
row_list.append(date_cell)
else:
#添加要写入行list中
row_list.append(cell_value)
#添加到要写入的list中
data.append(row_list)
#遍历要写入的数据,并给予新的索引
# list_index 新的行索引
# output_list 行中的数据列表
for list_index,output_list in enumerate(data):
# element_index 新的数据的列的索引
# element 数据元素
for element_index,element in enumerate(output_list):
#按行列定位写入数据
output_worksheet.write(list_index,element_index,element)
#保存关闭
output_workbook.save(output_file)
pandas
一种方式是在数据框名称后面的方括号中将列名以字符串方式列出。
另外一种方式是使用 loc 函数。如果使用 loc 函数,那么需要在列标题列表前面加上一个冒号和一个逗号,表示你想为这些特定的列保留所有行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
#打开输入文件对应的工作表
data_frame = pd.read_excel(input_file,'january_2013',index_col=None)
# 获取符合这两个标题的列
data_frame_column =\
data_frame[data_frame.iloc['Customer ID','Purchase Date']]
#根据列索引
# data_frame_column = data_frame.iloc[:,[0,4]]
#写入
writer = pd.ExcelWriter(output_file)
data_frame_column.to_excel(writer,sheet_name = 'jan_2013_output',index = False)
#保存
writer.save()
```
## 读取工作薄中的所有工作表
如何在一个工作薄的所有工作表中筛选特定的行与列?
#### 在所有工作表中筛选特定行
> 任务:筛选出工作表中销售额大于 $2000.00的所有行。
- 基础Python +xlrd + xlwt
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet(‘filtrrd_rows_all_worksheets’)
#保存 Sale Amount 列的索引值
sales_column_index =3
销售额阈值
threshold = 2000.00
判断是不是第一个工作表
first_worksheet = True
with open_workbook(input_file) as workbook:
data = []
#遍历文件中的所有工作表
for worksheet in workbook.sheets():
# 判断是不是第一个工作表
if first_worksheet:
# 取出标题行
header_row = worksheet.row_values(0)
# 添加标题
data.append(header_row)
first_worksheet = False
#从不是标题的地方开始迭代
for row_index in range(1,worksheet.nrows):
row_list = []
# 根据 行列索引 取出 销售额
sale_amount = worksheet.cell_value(row_index,sales_column_index)
# Sale Amount 列中的值与阈值比较
if sale_amount > threshold:
# 遍历符合条件工作表中的符合要求行中的数据
for column_index in range(worksheet.ncols):
#获取数据的值
cell_value = worksheet.cell_value(row_index,column_index)
#获取数据类型
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type ==3:
#日期类型数据转换格式化并添加到行list中
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,coutput_index in enumerate(data):
for element_index,element in enumerate(coutput_index):
#更具行列索引添加数据
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
1 |
|
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
# sheet_name=None 表示读取所有的工作表
# data_frame 是一个字典
data_frame = pd.read_excel(input_file,sheet_name=None,index_col=None)
row_output = []
#迭代
for worksheet_name,data in data_frame.items():
#添加符合要求的数据
row_output.append(data[data['Sale Amount'].astype(float) > 2000])
# axis=0 表示从头到尾垂直堆叠
# gnore_index 参数默认值为False,
# 如果为True,会对新生成的dataframe使用新的索引(自动产生),忽略原来数据的索引。
filtered_rows = pd.concat(row_output,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer,sheet_name='allsheet_outPut_Amount_get2000',index=False)
writer.save()
1
2
3
4
5
6
7
#### 在所有工作表中筛选特定列
> 任务:选取 Customer Name 和 Sale Amount 列
- 基础Python
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('filter_column')
#要保留的列
my_columns = ['Customer Name','Sale Amount']
#判断是不是第一个工作表
frist_worksheet = True
with open_workbook(input_file) as workbook:
data = [my_columns]
#保存要保留的列的索引值
index_of_cols_to_keep = []
for worksheet in workbook.sheets():
#是否在处理第一个工作表
if frist_worksheet:
header = worksheet.row_values(0)
for column_index in range(len(header)):
if header[column_index] in my_columns:
#标题索引值list
index_of_cols_to_keep.append(column_index)
frist_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
#只处理标题对应的列
for column_index in index_of_cols_to_keep:
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type==3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_index in enumerate(data):
for element_index,element in enumerate(output_index):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)
1
2
3
- pandas
使用 pandas 中的 read_excel 函数将所有工作表读入一个字典。然后,使用 loc 函数在每个工作表中选取特定的列,创建一个筛选过的数据框列表,并将这些数据框连接在一起,形成一个最终数据框。
import pandas as pd
import sys
input_file = sys.argv[1]
out_file = sys.argv[2]
data_frame = pd.read_excel(input_file,sheet_name=None,index_col=None)
column_output = []
for worksheet_name,data in data_frame.items():
#loc() 选取特定的列
column_output.append(data.loc[:, ['Customer Name', 'Sale Amount']])
selsected_columns = pd.concat(column_output,axis=0,ignore_index=True)
writer = pd.ExcelWriter(out_file)
selsected_columns.to_excel(writer,sheet_name="all",index=False)
writer.save()
1
2
3
4
5
6
7
8
9
10
11
12
## 在Excel工作薄中读取一组工作表
有时候,只需要处理Excel文件中的一部分表,比如有10张工作表,但是只需要处理其中的5张。
#### 在一组工作表中筛选特定行
> 任务:从第一个和第二个工作表中筛选出“销售额大于 $1900.00 的那些行
- 基础Python
`sheet_by_index` 或 `sheet_by_name` 函数来处理一组工作表。
import sys
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_file = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('group_line')
my_sheet = [0,1]
threshold = 1900.00
sales_column_index = 3
fristsheet = True
with open_workbook(input_file) as workbook:
data = []
for sheet_index in range(workbook.nsheets):
# 判断是不是需要的表
if sheet_index in my_sheet:
#根据索引获取工作表
worksheet = workbook.sheet_by_index(sheet_index)
#判断是不是第一次加载表
if fristsheet:
header_row = worksheet.row_values(0)
data.append(header_row)
fristsheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
#获取行中是金额的数据
sale_amount = worksheet.cell_value(row_index,sales_column_index)
#判断是否符合要求
if sale_amount > threshold:
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type ==3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)
1
2
- pandas
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
my_sheets = [0,1]
threshold = 1900.00
data_frame = pd.read_excel(input_file,sheet_name=my_sheets,index_col=None)
row_list = []
for worksheet_name, data in data_frame.items():
row_list.append(data[data['Sale Amount'].astype(float) > threshold])
filtered_rows = pd.concat(row_list,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer,sheet_name = 'all_line_group',index = False)
writer.save()
处理多个工作簿(多个Excel文件)
这里就要从新引入glob模块,来获得完整路径。
1. 工作表计数以及每个工作表中的行列计数
在有些时候我们不知道文件的内容。与csv文件不同的是,excel 文件可以包含多张工作表。所以 在处理之前获取一些关于工作表的描述性信息非常重要。比如:每个工作薄中的工作表数量。每张工作表中行列的数量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import glob,sys,os
from xlrd import open_workbook
input_directory = sys.argv[1]
workbook_count = 0
for input_file in glob.glob(os.path.join(input_directory,'*.xls*')):
workbook = open_workbook(input_file)
print('\n文件名 : %s' % os.path.basename(input_file))
print('表的个数: %d' % workbook.nsheets)
for worksheet in workbook.sheets():
print('表名:',worksheet.name,
'\t行数:',worksheet.nrows,
'\t列数:',worksheet.ncols)
workbook_count +=1
print('Number of Excel workbooks:%d' % workbook_count)

2. 从多个工作簿中连接数据
基础Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41import sys,os,glob
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
from datetime import date
input_folder = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('link_much_excel')
data = []
frist_worksheet = True
# 迭代文件夹中的文件
for input_file in glob.glob(os.path.join(input_folder,'*.xls*')):
print(os.path.basename(input_file))
with open_workbook(input_file) as workbook:
for worksheet in workbook.sheets():
if frist_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
frist_worksheet = False
for row_index in range(1,worksheet.nrows):
row_list = []
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index,column_index)
cell_type = worksheet.cell_type(row_index,column_index)
if cell_type==3:
date_cell = xldate_as_tuple(cell_value,workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
if row_list:
data.append(row_list)
for list_index,output_list in enumerate(data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index,element_index,element)
output_workbook.save(output_file)pandas
关键函数:
- concat() 函数来连接数据框
- axis = 0 垂直堆叠
- axis = 1 水平连接
merge()函数 可以提供类似SQL join 的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import pandas as pd
import sys,os,glob
input_folder = sys.argv[1]
output_file = sys.argv[2]
all_workbooks = glob.glob(os.path.join(input_folder,'*.xls*'))
data_frame = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook,sheetname=None,index_col=None)
for worksheet_name, data in all_worksheets.items():
data_frame.append(data)
all_data_concatenated = pd.concat(data_frame,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concatenated.to_excel(writer,sheet_name = 'all_group_all_workbooks',index = False)
writer.save()
- concat() 函数来连接数据框
3. 为每个工作簿和工作表计算总数和均值
- 基础Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import sys,glob,os
from datetime import date
from xlrd import open_workbook,xldate_as_tuple
from xlwt import Workbook
input_folder = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('sums_add_averages')
#输出文件的所有行
all_data =[]
#Sale Amount 的索引值
sales_column_index = 3
#文件标题列表
header = ['workbook',
'worksheet',
'worksheet_total',
'worksheet_average',
'workbook_total',
'workbook_average']
all_data.append(header)
#遍历文件中所有是 .xls* 的 文件
for input_file in glob.glob(os.path.join(input_folder,'*.xls*')):
#打开每次遍历到的文件
with open_workbook(input_file) as workbook:
list_of_totals = [] #保存所有的销售额
list_of_number = [] #销售额数据的个数
workbook_output = [] #输出文件的所有输出列表
#遍历文件中的工作表
for worksheet in workbook.sheets():
total_sales = 0
number_of_sales = 0
worksheet_list = [] # 保存工作表的信息
#添加工作簿名称和工作表名称
worksheet_list.append(os.path.basename(input_file))
worksheet_list.append(worksheet.name)
#遍历除标题以外的行
for row_index in range(1,worksheet.nrows):
try:#算总值
total_sales += float(str(worksheet.cell_value \
(row_index, sales_column_index)) \
.strip('$').replace(',', ''))
number_of_sales += 1.
except:
total_sales += 0
number_of_sales += 0
#算均值
average_sales = '%0.2f' % (total_sales / number_of_sales)
# 添加销售总计和均值
worksheet_list.append(total_sales)
worksheet_list.append(average_sales)
# 将工作表的销售额总计和销售额数据个数加紧对应列表
list_of_totals.append(total_sales)
list_of_number.append(float(average_sales))
# 在工作簿级别保存信息
workbook_output.append(worksheet_list)
# 使用两个列表计算出的工作簿的销售额总计和销售额均值
workbook_total = sum(list_of_totals)
workbook_average = sum(list_of_totals) / sum(list_of_number)
#将工作簿级别的销售额总计和均值追加到每个列表中
for list_element in workbook_output:
list_element.append(workbook_total)
list_element.append(workbook_average)
all_data.extend(workbook_output)
for list_index,output_list in enumerate(all_data):
for element_index,element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)
- pandas
pandas 可以直接在多个工作簿之间迭代,并可以同时在工作簿级别和工作表级别计算统计量。计算工作簿级别的统计量,将它们转换成一个数据框,然后通过基于工作簿名称的左连接将两个数据框合并在一起,并将结果数据框添加到一个列表中。当所有工作簿级别的数据框都进入列表之后,将这些数据框连接成一个独立数据框,并写入输出文件.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import pandas as pd
import sys,os,glob
input_path = '/Users/yyf/PycharmProjects/ReadTest/DataSouce/Excel'
output_file = '/Users/yyf/PycharmProjects/ReadTest/DataSouce/total_average.xls'
all_workbooks = glob.glob(os.path.join(input_path,'*.xls*'))
data_frames = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook,sheetname=None,index_col=None)
workbook_total_sales = []
workbook_number_of_sales = []
worksheet_data_frames = []
worksheets_data_frame = None
workbook_data_frame = None
for worksheet_name,data in all_worksheets.items():
total_sales= pd.DataFrame([float(str(value).strip('$').replace(',','')) for value in data.loc[:,'Sale Amount']]).sum()
number_of_sales = len(data.loc[:,'Sale Amount'])
average_sales = pd.DataFrame(total_sales/number_of_sales)
workbook_total_sales.append(total_sales)
workbook_number_of_sales.append(number_of_sales)
data = {'workbook':os.path.basename(workbook),
'worksheet':worksheet_name,
'worksheet_total':total_sales,
'worksheet_average':average_sales}
worksheet_data_frames.append(pd.DataFrame(data,columns=['workbook','worksheet','worksheet_total','worksheet_average']))
worksheets_data_frame = pd.concat(worksheet_data_frames,axis=0,ignore_index=True)
workbook_total = pd.DataFrame(workbook_total_sales).sum()
workbook_total_number_of_sales = pd.DataFrame(workbook_number_of_sales).sum()
workbook_average = pd.DataFrame(workbook_total / workbook_total_number_of_sales)
workbook_stats = {'workbook': os.path.basename(workbook),
'workbook_total': workbook_total,
'workbook_average': workbook_average}
workbook_stats = pd.DataFrame(workbook_stats, columns=['workbook', 'workbook_total', 'workbook_average'])
workbook_data_frame = pd.merge(worksheets_data_frame, workbook_stats, on='workbook', how='left')
data_frames.append(workbook_data_frame)
all_data_concatenated = pd.concat(data_frames,axis=0,ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concatenated.to_excel(writer,sheet_name ='sums_and_averages',index = False )
writer.save()